User Details
- User Since
- Apr 20 2018, 5:39 PM (312 w, 6 d)
Feb 26 2024
Feb 12 2024
Jan 26 2024
I have conducted additional testing. I can replicate the issue on a fresh VM. It seems the issue arises if the DHCP server is slow to respond upon bootup.
Jan 24 2024
Same results here. If I remove the routes and re-add them they work perfectly. The issue only comes up at reboot.
[email protected]:~$ show configuration commands | match 111.111.22.227 set protocols static route 111.111.22.227/32 dhcp-interface 'eth0'
Issue is back in 1.4.0-rc3
Dec 22 2023
Confirmed working properly in 1.4.0-rc1
Dec 8 2023
Oct 24 2023
Aug 29 2023
Jun 22 2023
May 31 2023
I checked 6 routers, 2 showed the issue. No idea what the impact is. All of them running 1.3.2.
May 25 2023
I could have sworn it took quite a while for the wlb.out to be populated when testing earlier on. However as I´ve built out the config a bit more I am now only able to reproduce it a few seconds after reboot - so your theory holds. Let's close out the bug report for now and I´ll reopen if something changes down the line.
May 23 2023
danhusan@vyos-1:~$ cat /var/run/load-balance/wlb.out cat: /var/run/load-balance/wlb.out: No such file or directory
May 22 2023
Further testing reveals that re-connecting the interfaces after reboot solves the issue:
Feb 14 2023
https://github.com/FRRouting/frr/pull/12364
riw777 merged commit 91b6db4 into FRRouting:master Feb 14, 2023
Oct 13 2022
Sep 18 2022
Sep 16 2022
Aug 11 2022
Jun 21 2022
Jun 20 2022
Wow, well done! You don't happen to have an ISO you could share?
Did you then end up with a fully working nic, bridging included?
Jun 16 2022
Feb 4 2022
Dec 21 2021
Confirmed working in 1.3.0 LTS.
Dec 18 2021
Can also confirm that 1.3.0-epa3 is broken, so something must have changed between epa3 and 202112180443.
Tried 1.3-beta-202112180443, seems to be working as it should now.
Nov 8 2021
Tested against 1.3.0-EPA3, same problem.
Oct 18 2021
Apr 12 2021
Thanks!
sudo journalctl -b
lspci -knn
@c-po I expected this to go into 1.2.7 but it did not. How would I tag this properly so it hopefully makes it into 1.2.8?
Apr 9 2021
Dec 26 2020
Dec 25 2020
Dec 23 2020
Oct 15 2020
This has come up multiple times before, see https://phabricator.vyos.net/T1698 for the solution.
May 28 2020
Reworking my config so that it uses eth0->eth3 instead of eth1->eth4 makes everything work as expected. So something has clearly changed regarding the interface naming/creation logic.
May 27 2020
VyOS added those during the 2nd boot after upgrade. I would assume bug related to the fact that my config doesn't include eth0.
May 26 2020
Sep 23 2019
Bump
May 14 2019
@syncer Any chance of getting this merged into 1.2.2?
Apr 23 2019
Any chance of getting this merged into 1.2.2?
Feb 23 2019
Feb 8 2019
Small config, just 4 interfaces with IPv4 and IPv6 + some BGP config. I am running the VyOS instance in ESXi with some fairly modern hardware.
Unfortunately I cannot just reboot this device at will. If you provide your email I can send over the config.
Jan 28 2019
Jan 27 2019
Jan 11 2019
No need to disable VNC :-) The FRR package should be fixed already so just need to make sure it is in EPA3.
The FRR devs have released binary packages including the fix and announced it on the FRR mailing lists. After considering the feedback on the list and discussing with FRR devs, we will postpone the experiments until Jan. 23rd, and have updated the schedule to reflect the delayed start and shorter timeline [A]. We will follow up with FRR devs and mailing lists/users.
Jan 8 2019
We plan to resume the experiments January 16th (next Wednesday), and have updated the experiment schedule [A] accordingly. As always, we welcome your feedback.
Wow, this explains why all my sessions dropped yesterday.
Jan 5 2019
Jan 4 2019
RC11 is getting old, please retry with latest rolling: https://downloads.vyos.io/rolling/current/amd64/vyos-1.2.0-rolling%2B201901040337-amd64.iso
Jan 2 2019
IPv6 seems to have the same issue. Peer shutdown in configuration, reboot, results below:
@c-po https://github.com/vyos/vyos-build/pull/35 is also needed. Without it upgrades (install image ...) will fail.
Added new pull requests, built and tested, working fine.
Dec 31 2018
Dec 28 2018
And FYI max-ipv6-routes=10 and max-ipv4-routes=10 doesn't seem to help either.
Dec 22 2018
Dec 20 2018
It is vmware-tools collecting all the routes from VyOS and reporting them to the hypervisor so you can see them in the ESXi GUI. Not really optimal for full tables.
Do you have a full bgp table on this box?
IIRC I worked around this by editing /etc/vmware-tools/tools.conf and adding:
And FYI, just to make sure that something wasn't triggered by hanging out in GRUB.
rootdelay=0 fails
rootdelay=2 works, so just a small pause is needed on my system at least.
@kroy you are clearly on a roll today, rootdelay=10 also did the trick.
Spot on, booting with acpi=off makes it come up properly and configurations are actually saved.
Still getting some errors but not sure if they matter or not:
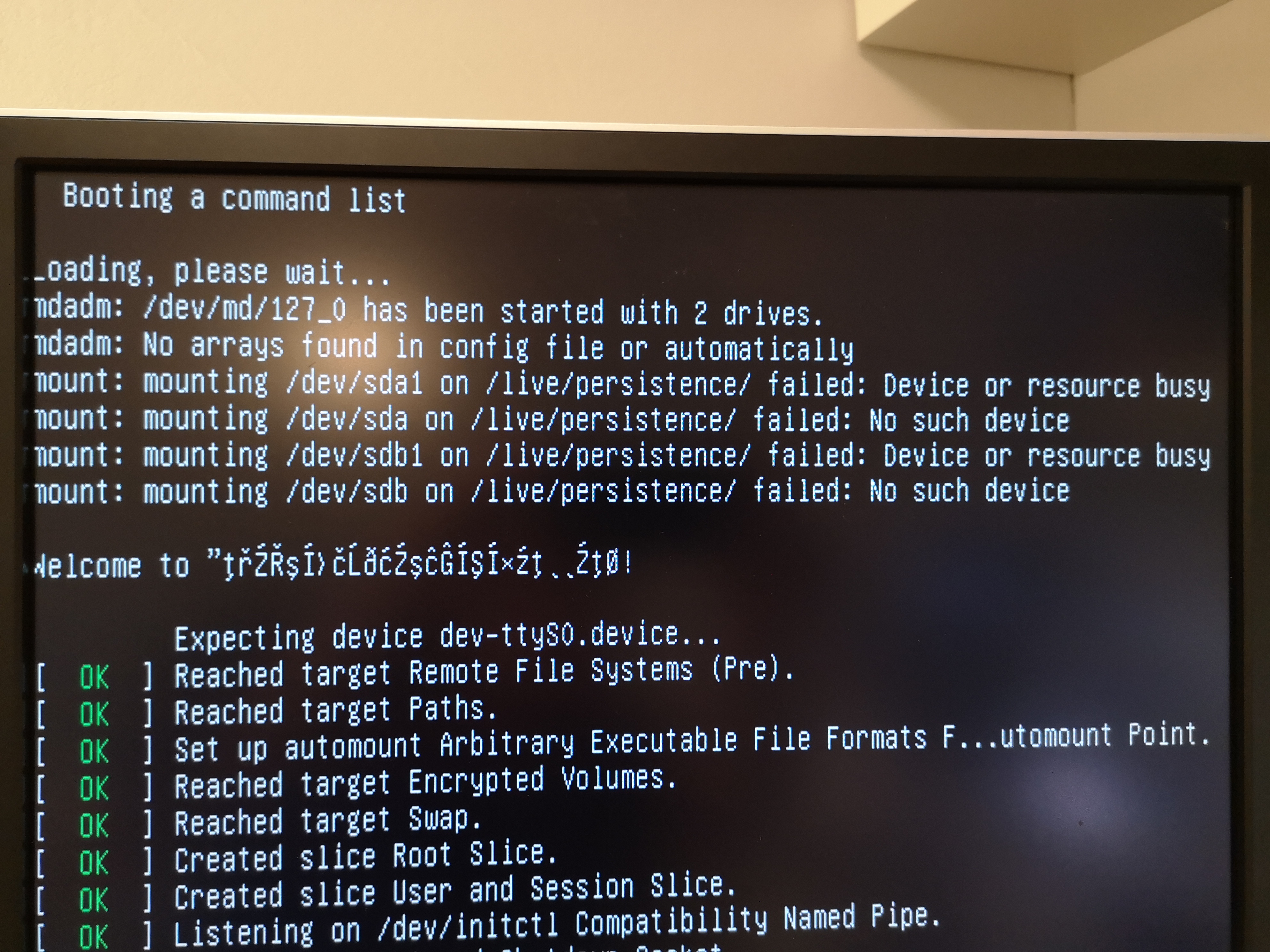
Some data I wasn't able to find in any log files:
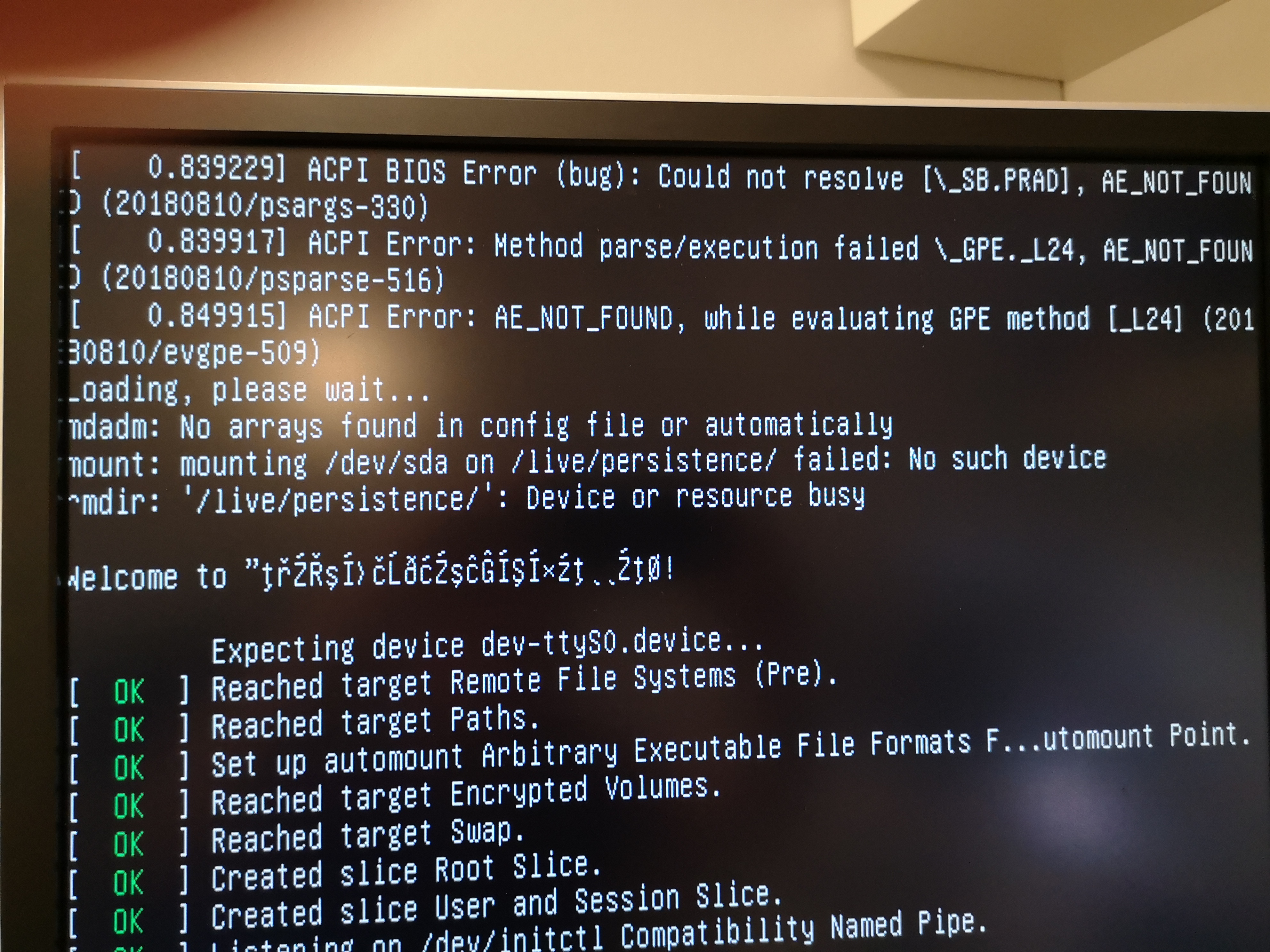
https://forum.vyos.io/t/vyos-1-2-0rc10-raid-1-fresh-install-unable-to-save-config/3059
These users might have the same issue. I noticed one of the symptoms of having the system is in this state is that the config is lost between reboots.
I am not able to reproduce it in vmware workstation.
I can let it sit forever, the status wont change as the array is missing one disk. Notice how after (auto read only) raid1 is only says sdb1[0] (sda1 is missing).
Also we can see that this wont fix itself from looking at the df -h output where the system clearly has booted straight from sda1 instead of from the raid array (/dev/md127)
Dec 19 2018
After reboot, running from local disks:
During install (booted from ISO):
Nov 9 2018
From 739d0815786aa642292335e47d14d99a34f0e68d Mon Sep 17 00:00:00 2001 From: Daniel Husand <[email protected]> Date: Fri, 9 Nov 2018 15:03:58 +0100 Subject: [PATCH] T982: soft-reconfiguration inbound now enables correctly on ipv4 peers
Nov 6 2018
From a70d2041bde216389b903eb273d3a09270d8f9aa Mon Sep 17 00:00:00 2001 From: Daniel Husand <[email protected]> Date: Tue, 6 Nov 2018 15:11:05 +0100 Subject: [PATCH] Fixed some typos to get ipv4 prefix-lists working again. Bug T968.
Nov 5 2018
My test env has been running for 50 minutes without the prefix-lists engaging so I'd say this is another issue. Furthermore I think the issue you are describing has been fixed in the upcoming rc6 (T944).
Oct 26 2018
Didn't know it existed, yes you are right. Thanks!