can reproduce ob EPA3:
Feed Advanced Search
Jan 25 2019
Jan 25 2019
syncer edited Description on VyOS 1.2 Crux.
Harliff updated the task description for T1198: Extra hyphen in suggested image name on upgrade.
Jan 24 2019
Jan 24 2019
rherold added a comment to T1196: Not able to set static IPv6 routes .
Jan 22 2019
Jan 22 2019
hagbard renamed T1194: cronjob is being setup even if not saved from conjobs is being setup even if not saved to conjob is being setup even if not saved.
kmpm added a comment to T1192: Wlan regression between 1.2.0-rc11 and rolling.
Hold back on this for a moment. Might be a hardware error since behaviour under rc11 is strange as well.
kmpm added a comment to T1192: Wlan regression between 1.2.0-rc11 and rolling.
Same issue with 1.2.0-rolling+201901070337 as well
Line2 added a comment to T1191: Ethernet interface with dhcp does not re-enable correctly after disable..
look at T1181
c-po added a comment to T1190: Separate out build-host setup shell commands from Dockerfile to shell script.
There are no disadvantages in doing so. Any contribution is welcome.
Jan 21 2019
Jan 21 2019
Jan 19 2019
Jan 19 2019
ekim added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
Absolutely -- I'll test it next week!
Jan 18 2019
Jan 18 2019
hagbard added a comment to T1184: wireguard - extend documentation with the show interface wireguard commands.
wireguard identifies peers on their key, improve the command for sh int wireguard wg01 peers etc. so that the peer name from the config is visible as well.
hagbard added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
@ekim https://downloads.vyos.io/rolling/current/amd64/vyos-1.2.0-rolling%2B201901181924-amd64.iso should address the dhcp issue, can you please test? I only tested on VMs yet.
hagbard changed the status of T894: DHCP not renewed after switching network, a subtask of T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient, from In progress to Needs testing.
hagbard triaged T1184: wireguard - extend documentation with the show interface wireguard commands as Low priority.
Jan 17 2019
Jan 17 2019
hagbard changed the status of T894: DHCP not renewed after switching network, a subtask of T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient, from Open to In progress.
Line2 added a comment to T1179: unhandled exception: show vpn ipsec sa.
I just tested this on 1.2.0-EPA3 and it works here. Please re-test with EPA3.
Jan 16 2019
Jan 16 2019
hagbard added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
All right @ekim I have that feature working in an experimental package. If you want to test it you can build it from here:
https://github.com/hagbard-01/vyos-netplug via dpkg-buildpackage -b -tc -uc -us and install it on any rolling iso. I used the latest for my tests, but it should work on older ones too. It will still take a little time to have that pushed into the normal build process, since it requires some integration work.
hagbard added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
@ekim Yeah, that is a known issue I was looking into a while ago already. disable/enable in eth interfaces should now work in the latest rolling, the plug-in and unplug will still need a little. I'll keep this task here open for it.
ekim added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
That’s correct, when deleting disable from the interface config. Additionally, It doesn’t seem like dhclient gets triggered when a physical interface is unplugged then plugged back into that same port, but should receive a new address as a different dhcp serving a different dinner is available
Jan 15 2019
Jan 15 2019
hagbard moved T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient from Need Triage to In Progress on the VyOS 1.2 Crux board.
hagbard renamed T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient from Stagnant IP on DHCP interface to disable/enable interface with dhcp ip assignement fails to restart dhclient.
hagbard changed the status of T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient from Open to Needs testing.
hagbard added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
@ekim I think I found it. When I put the interface into disabled mode and then delete disabled, the dhcp client isn't started anymore if the address is supposed to be received via dhcp, correct?
ekim added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
Yes, no issues on either DHCP server. All other clients on the network perform as expected.
hagbard added a comment to T1181: disable/enable interface with dhcp ip assignement fails to restart dhclient.
Have you checked on the server DHCP server side for issues?
Jan 14 2019
Jan 14 2019
ekim renamed T1179: unhandled exception: show vpn ipsec sa from unhandeled exception: show vpn ipsec sa to unhandled exception: show vpn ipsec sa.
Superseded by T1178
kroy added a comment to T1177: Unable to modify or delete task-scheduler tasks.
Seems to be a problem with just that build. I'll install a newer rolling when I get a chance and see if that corrects it.
kroy added a comment to T1177: Unable to modify or delete task-scheduler tasks.
Edit... actually I can't update anything:
Jan 11 2019
Jan 11 2019
Jan 10 2019
Jan 10 2019
Jan 9 2019
Jan 9 2019
Jan 7 2019
Jan 7 2019
kroy added a comment to T1169: LLDP potentially broken.
With VyOS as the edge:
kroy updated the task description for T1169: LLDP potentially broken.
hagbard added a comment to T1162: WireGuard: Unable to modify tunnels - KeyError: 'state'.
Next rolling will have the fix applied:
https://github.com/vyos/vyos-1x/commit/76fe726e3530158ee175d34b9cb74209ccca2345
Jan 6 2019
Jan 6 2019
hagbard changed the status of T1162: WireGuard: Unable to modify tunnels - KeyError: 'state' from Open to In progress.
bmtauer added a comment to T1157: Static route not reachable through VRRP address.
From the 1.2.0 instance (10.240.4.31) I'm able to ping the 1.1.8 (10.240.4.32) instance immediately after adding the address, but cannot ping out to the internet until after a reboot.
Merijn added a comment to T1157: Static route not reachable through VRRP address.
Do you mean the 31 and 32 also couldn’t ping eachother?
bmtauer added a comment to T1157: Static route not reachable through VRRP address.
This won't help in production case, as that uses a /30 network with only 2 possible addresses. One is the floating VRRP address and the other is the destination for the static route.
Jan 5 2019
Jan 5 2019
Jan 4 2019
Jan 4 2019
Merijn added a comment to T1157: Static route not reachable through VRRP address.
I see in the config that you do not have an interface IP on the VRRP members.
This works in 1.1.8 most of the time. But can you test if 1.2.0 works with those added. The hello source address is not needed then and the chances are the kernel wil load the connected route this way.
bmtauer updated the task description for T1157: Static route not reachable through VRRP address.
kroy added a comment to T1153: VyOS 1.2.0RC10, RAID-1, fresh install, unable to save config.
This is probably a duplicate of T1120, which should be fixed now.
danhusan added a comment to T1153: VyOS 1.2.0RC10, RAID-1, fresh install, unable to save config.
RC11 is getting old, please retry with latest rolling: https://downloads.vyos.io/rolling/current/amd64/vyos-1.2.0-rolling%2B201901040337-amd64.iso
Jan 3 2019
Jan 3 2019
patanne added a comment to T1142: l2tp remote access fails due to bad options in options.xl2tpd.
We have been waiting for 1.2 to roll for a long time. We have some running in Vyatta (Lenny), some on Vyatta (Squeeze), some on Vyos Hydrogen, and now a summer build from '18, plus RC7 & RC11. Trying to get packages to run the same way across all so change management is consistent has been fun.
c-po added a comment to T1142: l2tp remote access fails due to bad options in options.xl2tpd.
Thanks for the update. May I ask which distro?
patanne added a comment to T1142: l2tp remote access fails due to bad options in options.xl2tpd.
since we have the need to add some packages but not upgrade or interfere with what you have done, this does the trick.
patanne added a comment to T1142: l2tp remote access fails due to bad options in options.xl2tpd.
we write a lot of packages for ourselves that are in our own repo. we layer them on top of your distro. someone probably issued a global upgrade, rather than for just our stuff.
c-po added a comment to T1142: l2tp remote access fails due to bad options in options.xl2tpd.
cpo@BR1:~$ dpkg --list | grep xl2tp ii xl2tpd 1.3.6+dfsg-2-vyos0 amd64 layer 2 tunneling protocol implementation
patanne added a comment to T1142: l2tp remote access fails due to bad options in options.xl2tpd.
digging a little deeper, all installations having this issue also have had the package xl2tpd replaced. you ship with 1.3.6+dfsg-2-vyos0. somehow it got replaced with 1.3.8+dfsg-1~bpo8+1
Jan 2 2019
Jan 2 2019
Merijn added a comment to T1149: flow-accounting stops on 1.2.0-epa2.
Solved by disabling engine ID when the version is 9, not sure if this is enough but on my router it works.
Merijn added a comment to T1149: flow-accounting stops on 1.2.0-epa2.
Until version 1.7.0 it was possible to (mistakenly) configure the
NetFlow v9 SourceID field/IPFIX Observation Domain ID with the old
NetFlow v5 jargon, ie. '1:1'. This is now threated as invalid and
a positive 32-bit number, ie. '100000', is expected. If exporting
NetFlow v5, nothing changed: the Engine ID/Engine Type input, ie.
'1:1', is still valid and expected.
Merijn added a comment to T1148: epa2 BGP peers initiate before config is fully loaded, routes leak..
This behavior was already present in the old Quagga implementation in Vyos 1.1.7.
As a workaround we always shutdown the peers when doing a planned reboot.
danhusan added a comment to T1148: epa2 BGP peers initiate before config is fully loaded, routes leak..
IPv6 seems to have the same issue. Peer shutdown in configuration, reboot, results below:
Dec 31 2018
Dec 31 2018
Dec 28 2018
Dec 28 2018
zsdc added a comment to T1135: "firewall send-redirects enable" works only after switching from disabled state on running system.
I've made some tests...
I have build a lab with next configuration:
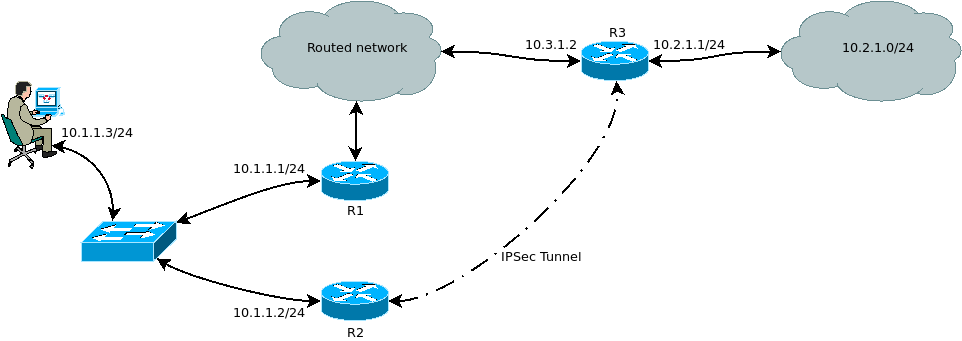
In test PC gateway to 10.2.1.0/24 is R2.
In R2 we have next routing tables:
vyos@vyos:~$ show ip route
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB routec-po added a comment to T1142: l2tp remote access fails due to bad options in options.xl2tpd.
Can you share your configuration please? I use rc11, too as l2tp/ipsec access concentrator and everything is fine here.
patanne updated the task description for T1142: l2tp remote access fails due to bad options in options.xl2tpd.
Dec 27 2018
Dec 27 2018
hagbard added a comment to T1135: "firewall send-redirects enable" works only after switching from disabled state on running system.
I have a look into it but I doubt that this will be an issue. Charon is usually taking care of the routes if an IPSec tunnel has been established and you have a valid SA. The redirects from the settings above shouldn't interferer with it at all. If a mode tunnel is being used with public IPs, the packets will leave the system unencrypted anyway as long as no valid SA exists, so they will go the default route. I'll check if the perl script is actually changing these settings, that would be not so nice since you will face a race condition which would explain why I can't reproduce your issue, since I never tested with a working IPSec tunnel :). I'm having the flu right now, so please give me a few days to have a look.
zsdc added a comment to T1135: "firewall send-redirects enable" works only after switching from disabled state on running system.
I found. This is VPN settings.
Based on information from Linux IP stack flow diagrams, IPSec policy applying after route decision, and ICMP redirects doing before this. So we can't leave send_redirects=1 on interface, where we receive unencrypted traffic for IPSec.
But, we can:
- Check for firewall send-redirects 'enable' and prevent to commiting vpn ipsec options, when send_redirects is enabled.
- Disable send_redirects only on interfaces, where we expect incoming unencrypted IPSec traffic.
I'm not sure, what is better.
Dec 26 2018
Dec 26 2018
hagbard added a comment to T1135: "firewall send-redirects enable" works only after switching from disabled state on running system.
Can you check ig you have any postscripts running or any manual sysctl variable set? Or do you experience that on new insatllations?